Stream Analytics Manager in Hortonworks Data Flow - 2
Stream Analytics Manager의 component들에 대한 정리
Component는 Source(Input) -> Processor(Processing) -> Sink(Output) 순으로 처리가 이루어 진다.
1. Source Component
- 현재 Event Hubs, HDFS, Kafka 3개의 기능만 제공하고 있다.
1) Event Hubs : MS Azure에서 제공하는 이벤트를 수집, 변환, 저장하는 하이퍼 스케일 원격 분석 수집 서비스

2) HDFS : HDFS URL을 통하여 HDFS 디렉토리에 있는 파일을 Import 함
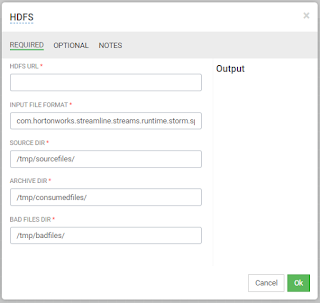
3) Kafka : 분산 메세징 큐 서비스인 Kafka를 Source로 이용, Kafka Topic을 만든 뒤 해당 정보를 Schema Registry에 해당 Topic 정보를 입력하고 사용.

2. Processor Component
- Aggregate, Branch, Join, Projection, Rule, PMML(Predictive Model Markup Language) 6개의 기능 제공.
1) Join : 2개의 Source에서 들어오는 데이터를 Join한다. Interval을 시간 or Count로 조정하여 수행, Output 컬럼을 지정할 수 있다.

2) Aggregate : AVG, COUNT, SUM, MAX, MIN등 의 aggregate function을 사용하여 들어오는 데이터를 조작, 역시 Output 컬럼을 지정할 수 있다.

3) Rule : 어떠한 Rule을 지정하여 데이터를 filtering 한다. EQUALS, NOT_EQUAL, GREATER_THAN, LESS_THAN 등. 비교연산자를 생각하면 될 것 같다.

4) Projection : IDENTITY, UPPER, LOWER, INITCAP, SUBSTRING, CONCAT, CHAR_LENGTH 함수를 제공

5) Branch : 어떠한 Rule을 지정하여 데이터를 양방향 Stream으로 나누어 준다.

6) PMML(Predictive Model Markup Language) : SAM에 등록한 PMML을 이용하여 데이터를 분석한 뒤 결과 값을 Ouput으로 내보낸다. Model Registry 탭에서 PMML을 등록 가능하다.

3. Sink Component
- 다른 시스템으로 이벤트를 전송하는데 사용, HDFS, HIVE, HBASE, KAFKA, CASSANDRA, JDBC, SOLR, TSDB, DRUID, NOTIFICATION(SMTP) 등등
* DB(Hive,Hbase 등)의 경우 일반적인 Configuration과 URL, DB Name, Table Name 그리고 Output 정도만 설정하여 주면 된다. 아래는 Hive 설정 예시
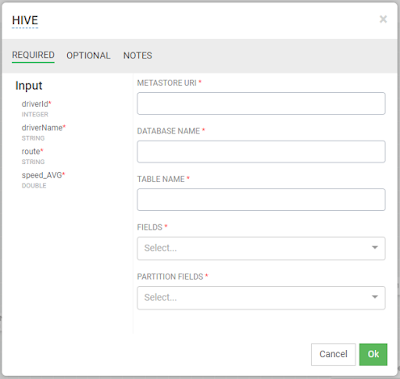
* NOTIFICATION의 경우도 일반적인 SMTP 설정과 같음. E-mail의 내용에 Input으로 받은 정보를 사용할 수 있다. ex) eventTime is ${컬럼명}

Component는 Source(Input) -> Processor(Processing) -> Sink(Output) 순으로 처리가 이루어 진다.
1. Source Component
- 현재 Event Hubs, HDFS, Kafka 3개의 기능만 제공하고 있다.
1) Event Hubs : MS Azure에서 제공하는 이벤트를 수집, 변환, 저장하는 하이퍼 스케일 원격 분석 수집 서비스

2) HDFS : HDFS URL을 통하여 HDFS 디렉토리에 있는 파일을 Import 함
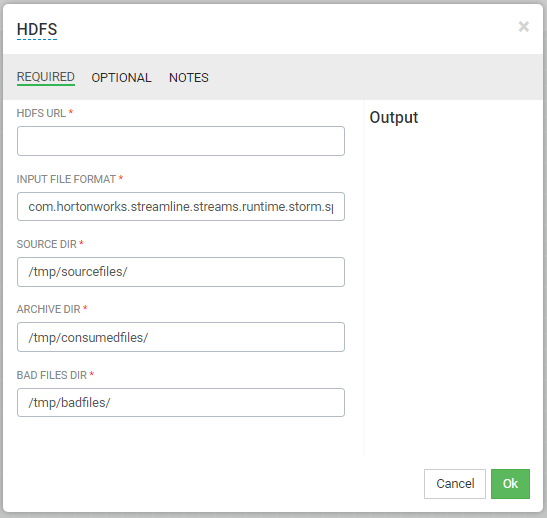
3) Kafka : 분산 메세징 큐 서비스인 Kafka를 Source로 이용, Kafka Topic을 만든 뒤 해당 정보를 Schema Registry에 해당 Topic 정보를 입력하고 사용.

2. Processor Component
- Aggregate, Branch, Join, Projection, Rule, PMML(Predictive Model Markup Language) 6개의 기능 제공.
1) Join : 2개의 Source에서 들어오는 데이터를 Join한다. Interval을 시간 or Count로 조정하여 수행, Output 컬럼을 지정할 수 있다.

2) Aggregate : AVG, COUNT, SUM, MAX, MIN등 의 aggregate function을 사용하여 들어오는 데이터를 조작, 역시 Output 컬럼을 지정할 수 있다.

3) Rule : 어떠한 Rule을 지정하여 데이터를 filtering 한다. EQUALS, NOT_EQUAL, GREATER_THAN, LESS_THAN 등. 비교연산자를 생각하면 될 것 같다.

4) Projection : IDENTITY, UPPER, LOWER, INITCAP, SUBSTRING, CONCAT, CHAR_LENGTH 함수를 제공

5) Branch : 어떠한 Rule을 지정하여 데이터를 양방향 Stream으로 나누어 준다.

6) PMML(Predictive Model Markup Language) : SAM에 등록한 PMML을 이용하여 데이터를 분석한 뒤 결과 값을 Ouput으로 내보낸다. Model Registry 탭에서 PMML을 등록 가능하다.

3. Sink Component
- 다른 시스템으로 이벤트를 전송하는데 사용, HDFS, HIVE, HBASE, KAFKA, CASSANDRA, JDBC, SOLR, TSDB, DRUID, NOTIFICATION(SMTP) 등등
* DB(Hive,Hbase 등)의 경우 일반적인 Configuration과 URL, DB Name, Table Name 그리고 Output 정도만 설정하여 주면 된다. 아래는 Hive 설정 예시
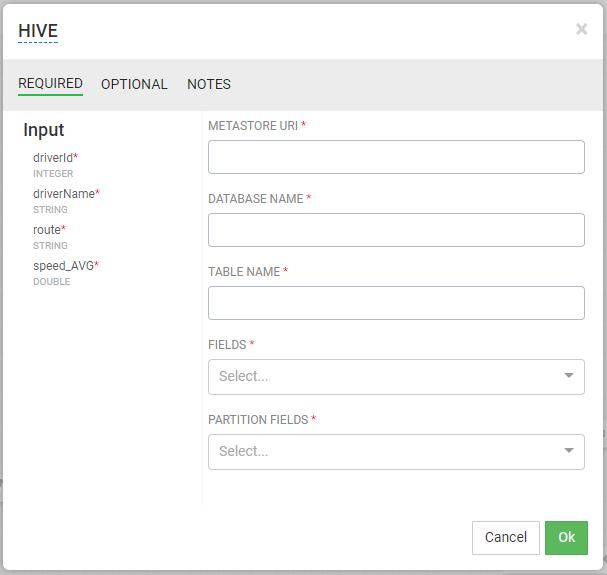
* NOTIFICATION의 경우도 일반적인 SMTP 설정과 같음. E-mail의 내용에 Input으로 받은 정보를 사용할 수 있다. ex) eventTime is ${컬럼명}

댓글
댓글 쓰기